Non bloccare le query spam [case study]
by 16 Novembre 2022 9:090
Oggi ti scrivo di un errore che ho commesso sul sito web di un cliente, costato l’indicizzazione di circa 3.000 URL spam. Lo faccio per due motivi, il primo è che non ho nulla da nascondere, il secondo è che il fenomeno è interessantissimo da studiare e mostrare.
Non vi dirò a quale sito web si fa riferimento, né il segmento di mercato in cui opera, perché non è importante in questo caso, ma soprattutto perché tengo molto alla privacy delle aziende che seguo.
Scenario
Mi viene chiesto di studiare la versione italiana e quella tedesca di un sito web multilingua. Nella copertura indice della proprietà italiana trovo circa 3.000 percorsi che fanno riferimento a query di ricerca SPAM lanciate allo scopo di far scansionare link a siti web di casinò online e altre amenità.

Le risorse in questione erano tutte nel percorso /search/ ed ?s=. Mi accorgo che le ultime richieste per queste risorse risalgono al mese precedente, quindi do per scontato che al momento siano ferme, dunque per evitare che queste pagine già escluse vengano richieste in futuro, suggerisco di bloccare i percorsi attraverso il file robots.txt.
A parte ciò, l’agenzia che segue il sito web fa in modo che queste richieste generino automaticamente uno status 404, quindi tagliamo proprio la testa al toro.
Due giorni dopo aver bloccato i percorsi, vengo contattato dal marketing manager che mi avverte di un picco di pagine indicizzate nella versione in inglese del sito web.
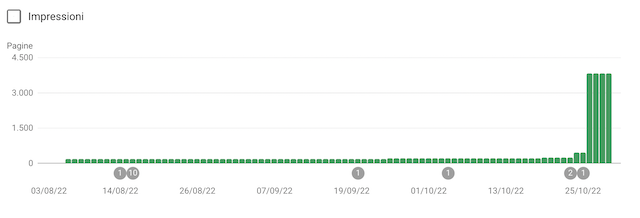
Non avendo studiato la versione in lingua inglese del sito web, corro ad aprire la Search Console e scopro che in quel caso le query spam escluse dall’indice non erano 3.000, ma circa 10 volte di più. Di queste, circa 3.000 erano entrate in indice – indicizzate, ma bloccate da robots.txt – immediatamente dopo l’inserimento della direttiva di blocco dei percorsi di ricerca. Le pagine in questione erano peraltro tutte 404. Ma com’era possibile?
Cosa ci era capitato
Facciamo una piccola premessa: le pagine di ricerca su WordPress hanno normalmente un codice 200 (pagina raggiungibile) e un meta robots impostato su noindex. Nel nostro caso avevano uno status 404, quindi ci sentivamo anche tranquilli… in effetti troppo.
Il processo di indicizzazione comprende varie fasi, che potremmo riassumere (e semplificare) in tre step:
- Rilevazione: Google prende atto che una pagina esiste
- Scansione: Google legge il contenuto della pagina (e il codice)
- Indicizzazione: Google lista la pagina nei risultati di ricerca
Nel nostro caso, Google aveva rilevato le 3.000 pagine prima che fossero messe in status 404 e prima che fosse inserita la direttiva di blocco nel file Robots.txt. Quando le pagine sono passate dalla fase di rilevazione a quella di scansione, c’era già il disallow dei percorsi di ricerca, quindi Google non ha potuto vedere niente. Di solito in queste circostanze l’indicizzazione comunque non avviene, perché Google sposta questo tipo di risorse tra le pagine escluse in quanto Rilevate, ma attualmente non indicizzate, invece no, le ha messe in indice comunque.
È dunque una situazione abbastanza rara – e per questo mi fa piacere raccontarvela – In questo caso dipesa dal fatto che sulla versione in lingua inglese c’era un grosso bombardamento di query spam, evidentemente anche molto frequente. Per risolvere il problema basta escludere le direttive di blocco dal file robots.txt per ripristinare la situazione, sperando che Google sia tanto veloce a escludere le risorse in questione, quanto lo è stato a indicizzarle.
Hai presente quando pur segnalando ogni giorno le pagine nuove, Google ti fa aspettare mesi per indicizzarle? Roba da far prudere le mani, ma sul serio.
Related posts

Ottimizzazione SEO / by - 1 Settembre 2025 18:14
Come fare SEO per un blog aziendale (e quando non farla)
Lo dico senza giri di parole: il blog aziendale non è un obbligo morale. È uno strumento. Se i conti non tornano tra costi, canali e probabilità di clic, meglio…

Ottimizzazione SEO / by - 1 Settembre 2025 17:34
SEO multilingua, quello che le agenzie non dicono
Lo dico subito: non sempre ti conviene.Molti colleghi ti diranno “almeno 4 lingue e via”. È un classico: più lingue = più ore = più fatturato.Un consulente SEO coscienzioso, invece,…