Trovare e tagliare i contenuti inutili
by 14 Luglio 2017 7:5816
Ultimo aggiornamento 19 Aprile 2024
Sono quelle pagine che allontanano il tuo progetto web dai significati per i quali viene riconosciuto e classificato da Google. Per capirci, se il tuo blog sulla SEO contiene 100 articoli, di cui 70 parlano di taglio e cucito, c’è qualcosa che non va.

La situazione è molto diffusa. Ne accennavo l’altro ieri parlando del piano editoriale SEO: gli articoli che non seguono il piano editoriale, quelli “estemporanei” possono appesantire la struttura di scansione portando i posizionamenti a peggiorare via via che aumentano di numero. Ma come fare a capire quali sono dopo anni di pubblicazioni miste?
Semplice, chiedi a Google
Occorre verificare l’eventuale discrasia tra pagine indicizzate e pagine che ricevono traffico. Il primo passaggio è controllare lo stato dell’indicizzazione sulla Search Console e confrontare questo numero con quello delle pagine indicizzate secondo l’operatore di ricerca site:
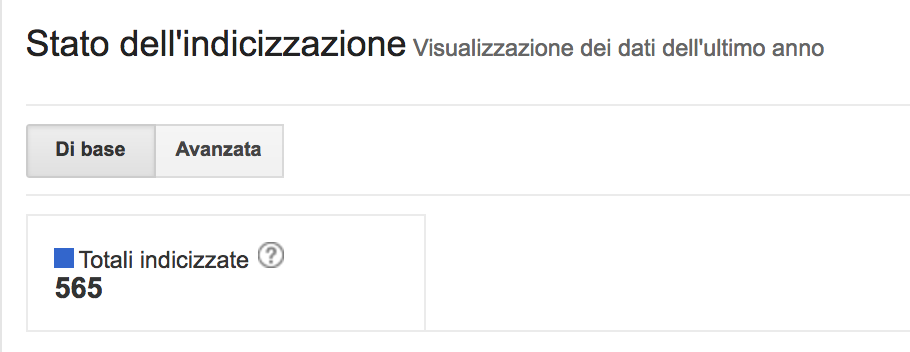
Operatore di ricerca site:

Nel primo caso Google dichiara 565 pagine indicizzate, nel secondo 569, quindi i valori sono sostanzialmente allineati, ma questo non vuol dire che Google ritenga tutti i miei articoli meritevoli di traffico. Per verificare puoi aprire Google Analytics e compiere il seguente passaggio:
Comportamento –> Contenuti –> Pagine di destinazione
Dimensione secondaria –> Acquisizione –> Sorgente mezzo
Richiamando i primi 1.000 risultati avrai tutte le pagine del tuo sito web con tutte le sorgenti di traffico. A questo punto devi filtrarle per sorgente Google / Organic, escludendo le altre. Ora hai tutte le pagine del tuo sito web che ricevono “effettivamente” traffico da motore di ricerca, nel mio caso solo 391 articoli ricevono traffico da Google, gli altri no.
Come individuare di preciso le pagine
A questo punto non ti resta che procedere per differenza. Io utilizzo Screaming Frog per estrarre in formato excel tutti gli URI (gli URI sono gli indirizzi web subito dopo il primo slash) delle pagine del mio blog. Di fianco a questa colonna incollo quella scaricata da Google Analytics, comprendente tutti gli URI che ricevono traffico. Una volta cancellati i contenuti ripetuti (con un filtro excel) tra le celle delle due colonne, ho una lista esatta delle pagine web che evidentemente non piacciono a Google.
Nel mio caso la maggior parte delle pagine in questione sono editoriali e pagine di diario, dal momento che a me piace raccontare anche un po’ la mia vita attraverso il blog. Ora posso decidere cosa farne, se accorpare, tagliare, modificare o lasciare tutto com’è.
Su siti web più grandi questo lavoro può richiedere mesi, ma ti assicuro che una volta fatto, migliora davvero le cose.
Un’altra bella caccia al tesoro!
Related posts

Ottimizzazione SEO / by - 31 Luglio 2024 11:40
Analisi dei Log sul Server: come aiuta per la SEO
Ultimo aggiornamento 31 Luglio 2024 L’analisi dei log sul server è una pratica davvero utile per ottimizzare la SEO di un sito web. Questa attività consente di ottenere informazioni dettagliate…

Ottimizzazione SEO / by - 17 Novembre 2023 9:25
SEO Audit, cos’è e quando farlo
Ultimo aggiornamento 19 Aprile 2024 Introduzione L’SEO audit è una pratica fondamentale per migliorare la visibilità online di un sito web e ottimizzarne il rendimento nei motori di ricerca. È…